> SQL 등 코딩 연습할 수 있는 사이트:
코딩은 이론보다 실습하면서 많이 틀리면서 배우는 것이기 때문에 코딩 연습으로 유명한 프로그래머스에서 sql 코딩을 연습해보았다. 처음 만난 문제가 유독 난이도가 어려웠어서 당황했다. 오늘은 유독 어려웠던 문제를 하나 풀이해보면서 til 작성을 시작하고자 한다.
문제: 대장균들의 자식의 수 구하기

https://school.programmers.co.kr/learn/courses/30/lessons/299305
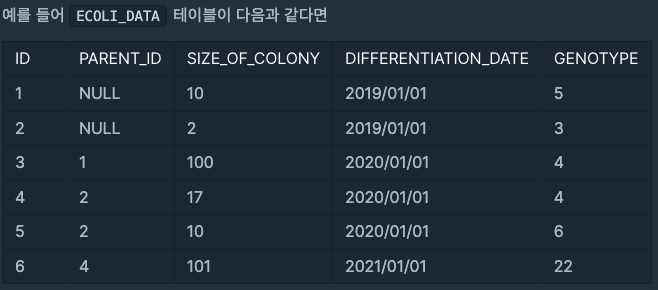
문제
대장균 개체의 ID(ID)와 자식의 수(CHILD_COUNT)를 출력하는 SQL 문을 작성해주세요. 자식이 없다면 자식의 수는 0으로 출력해주세요. 이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요.
이름부터 당황스러운 대장균들의 자식 수 구하기... 어느 연구실에서나 재조합 DNA 뽑을 때 대장균 참 잘도 써먹었는데 ㅋㅋ 묘하게 추억돋기도 하고 ㅎ
이 문제가 재밌는게, 단순히 코딩 능력 뿐 아니라 문제를 접근할 때도 약간 생각을 해봐야 한다. (처음엔 뭔 수수께끼를 푸나 싶었다.)
ECOLI_DATA 테이블을 보면, ID와 PARENT_ID 변수가 있다. ID는 개체 하나하의 ID이고, PARENT_ID는 그 개체의 부모 ID이다.
그래서 자식 수를 구하려면 PARENT_ID를 통해서, 즉 각 자식ID의 부모ID가 뭐냐를 역으로 추적해서 각 PARENT_ID의 자식 수를 구해야 한다. 그러니까 문제를 이렇게 풀어볼 수 있다.
> 문제풀이
문제: 자식의 수 구하기 -> 각 자식 당 주어진 부모 정보를 이용하여, 그 부모의 자식의 수 구하기
여기까지 파악했으면 이제 코드로 구현하면 된다.
1. 가장 먼저 "각 부모가 가진 자식의 수"를 출력하는 코드를 짜보자.
select PARENT_ID, count(*) as CHILD_COUNT
from ECOLI_DATA
group by PARENT_ID부모를 기준으로 수를 셀 것이므로 group by PARENT_ID로 기준을 두어 계산한다.
(PARENT_ID가 1인 경우 -> 1, PARENT_ID가 2인 경우 -> 2. PARENT_ID가 3인 경우 ->0 ... 이런 결과를 내고 싶으니까 group by 뒤에는 PARENT_ID가 와야 함)
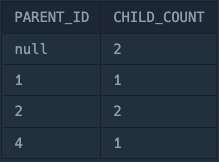
그럼 이런 결과가 나온다. 문제에서 요구한 CHILD_COUNT의 값을 구했다.
자식 수만 구하면 되면 이러고 끝이지만, 문제에서 대장균 개체의 ID도 함께 출력하라고 했다. 또한 자식이 없다면 자식의 수는 0으로 출력해달라고 했다. 결과는 개체의 ID로 오름차순 정렬.
2. 서브쿼리 문과 left join을 이용하여 ID에 해당하는 CHILD_COUNT를 매칭시켜주자. 그리고 null일 경우에 0으로 처리해달라는 함수인 IFNULL()을 활용하자.
select p.ID, IFNULL(c.CHILD_COUNT, 0) as CHILD_COUNT
from ECOLI_DATA p
left join (
select PARENT_ID, count(*) as CHILD_COUNT
from ECOLI_DATA
group by PARENT_ID
) c
on p.ID = c.PARENT_ID
order by p.ID
이렇게 하면 대장균의 ID 별로 몇마리의 자식이 존재하는지 알 수 있다.
어휴...진짜 복잡하다. ㅎㅎ(사실 블로그에 적을려고 또 복습을 했는데도 쉽지가 않았다.)
+ 참고로 다음 정답도 존재한다.
select p.ID, count(c.PARENT_ID) as CHILD_COUNT
from ECOLI_DATA as p left join ECOLI_DATA as c on p.ID = c.PARENT_ID
group by p.ID
order by p.ID참고로 count(변수)는 null일 경우에 알아서 0으로 세어준다고 한다.
이 때 count(*)로 바꿀 경우 null을 포함해서 전체 행 수를 센다고 하니 주의하자.
| COUNT(*) | NULL 포함해서 전체 행 수 셈 |
| COUNT(컬럼) | 해당 컬럼이 NULL이 아닌 것만 셈 |
이 쿼리에서는 COUNT(C.ID) → 자식이 없으면 NULL → → 0으로 잘 나옴!
그래서 따로 IFNULL() 같은 처리 안 해줘도 된다.
어려웠던 점
1. 서브쿼리와 Join문
inner join이나 left join을 두 테이블을 합치는데 쓸 수 있다는 것은 알았는데, 서브쿼리문과 합칠 수 있다는 것을 처음 알았다. gpt에 물어보니 다음과 같은 상황에서 자주 쓰이는 기법이라 한다.
> GPT 대답
👀 이런 구조 자주 봐:
SELECT a.컬럼, b.집계값
FROM 원본테이블 a
LEFT JOIN ( SELECT 기준컬럼, 집계함수 FROM 원본테이블 GROUP BY 기준컬럼 ) b
ON a.기준컬럼 = b.기준컬럼이 패턴은 특히 이런 상황에서 자주 써:
- 특정 컬럼 기준으로 **집계한 값(카운트, 평균 등)**을
- 다시 원래 테이블에 붙여서
- 전체 정보 + 집계값을 한 줄에 같이 보고 싶을 때!
그리고 개인적으로 on의 기준도 좀 헷갈려서 공부해봤는데 아래와 같다고 한다.
2. ON절의 기준
왜 e.ID = c.PARENT_ID일까?'
> GPT 대답
이건 두 테이블의 연결 기준 (매칭 조건)을 정해주는 부분이야.
위 문제에서:
- e.ID → 개체 하나하나의 ID
- c.PARENT_ID → 집계한 서브쿼리에서, 어떤 부모가 자식을 몇 명 가졌는지를 나타냄
→ 그러니까, e 테이블의 “이 개체가 부모인 경우”에, 자식 수를 붙여주는 거야!
"이 ID가 부모로 등장한 적이 있으면 → 자식 수 붙이고,
없으면 → 0으로 처리해!"
정리하면, ON 절은 "내가 어떤 기준으로 두 테이블을 연결할 건지"를 염두해 두고, 두 테이블에서 논리적으로 연결될 수 있는 컬럼끼리 매칭시켜주는 거라고 한다.
오늘은 프로그래머스에 있는 sql 코딩 테스트 Lv3 문제들을 풀어보고, 제일 인상깊고 머리 아팠던 문제 하나를 가져와봤다. 코딩 예제는 끝도 없구나를 느낀다 ㅎ 그래도 여러번 연습하다보면 언젠가 sql 코딩 꽤 잘하는 사람이 되어있지 않을까 싶다.
'SQL 코딩연습' 카테고리의 다른 글
| DISTINCT와 한 ID가 여러 정보를 갖고 있을 때 주의할 점 (1) | 2025.04.04 |
|---|---|
| 삼중쿼리와 where ~ in 구문 (0) | 2025.04.03 |