패스트캠퍼스 환급챌린지 46일차: <세계 3등에게 배우는 실무 밀착 데이터 시각화> 강의 후기
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.



강의 후기 및 인사이트
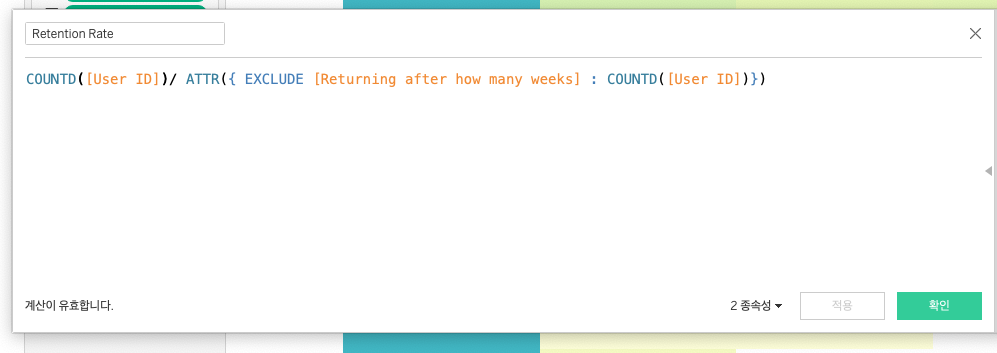
오늘은 Cohort Chart(코호트 차트)를 활용해 리텐션 분석을 시각화하는 실습을 진행했다. 특히 인상적이었던 부분은 리텐션율을 계산하기 위한 계산식 구성이었는데, 그 중심에는
COUNTD([User ID]) / ATTR({ EXCLUDE [Returning after how many weeks] : COUNTD([User ID]) })라는 식이 있었다.
이 계산식은 각 주차별로 재방문한 유저 수를, 최초 유입된 해당 주차의 유저 수로 나누는 방식인데, 여기서 EXCLUDE LOD(Level of Detail) 계산을 통해 리텐션 기간 구간을 제외한 분모 집계값을 별도로 지정하는 점이 굉장히 유용하다고 느꼈다.
또한, ATTR() 함수는 다소 생소했지만 단일 값을 보장하면서도 집계함수 내에서 특정 계산을 할 수 있도록 도와주는 유연한 함수라는 점에서 다양한 곳에 활용 가능하겠다는 인사이트를 얻었다. 지금까지는 보통 비율 계산을 위해 일반적인 SUM이나 COUNT 정도만 사용해왔는데, EXCLUDE와 ATTR을 조합하니 계층을 달리한 데이터 집계를 동시에 조작할 수 있다는 점이 새로웠다.
PM 입장에서 이러한 Cohort Chart는 단순한 리텐션 수치 이상의 의미를 가진다. 유입된 시점별로 사용자들의 이탈 패턴을 한눈에 확인할 수 있기 때문에, 온보딩 설계 개선, 마케팅 메시지 타이밍 조정, 기능 업데이트 전후 효과 분석 등 다양한 비즈니스 판단에 근거가 될 수 있다. 오늘 실습은 단순한 시각화가 아닌, 구조화된 계산과 분석 설계를 통해 실제 제품 전략에 적용 가능한 리텐션 분석을 구현하는 경험이었다.